
作为普通用户,我们如何看待并使用AI?
作为普通用户,我们如何看待并使用AI?随着 DeepSeek 问世,从春节至今,和AI有关的资讯与讨论已经让人有些疲劳。然而,相关讨论大都聚焦在产业、投资和技术方面,其中不乏优质信息,但仍缺少一个重要的视角——作为普通用户,我们如何看待并使用AI。
来自主题: AI资讯
7049 点击 2025-03-05 08:40
 搜索
搜索
随着 DeepSeek 问世,从春节至今,和AI有关的资讯与讨论已经让人有些疲劳。然而,相关讨论大都聚焦在产业、投资和技术方面,其中不乏优质信息,但仍缺少一个重要的视角——作为普通用户,我们如何看待并使用AI。

在 DeepSeek 生成的文本中,有 74.2% 的文本在风格上与 OpenAI 模型具有惊人的相似性?这是一项新研究得出的结论。这项研究来自 Copyleaks—— 一个专注于检测文本中的抄袭和 AI 生成内容的平台。

风险投资行业中,古典 VC 在科技创新浪潮中捕捉机会追求胜率,讲究品牌效应、二八原则和师徒传承。过去几年,VC 行业集体丧失贝塔,无法抓住阿尔法的 VC 已经被汰换,传统 VC 模式的弊端也逐渐暴露。VC 模式的换代迎来了 Deepseek 时刻。
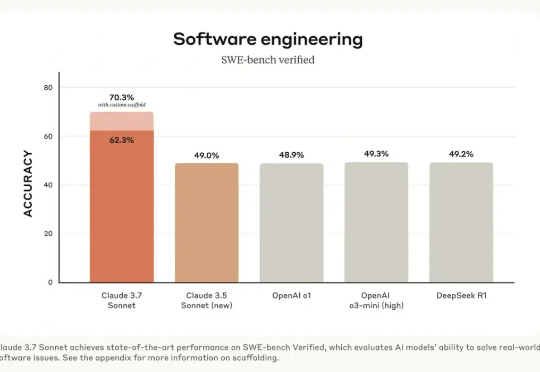
昨天,Claude 3.7 Sonnet 正式发布。根据目前的各项测评,这个模型可以说是全宇宙最好的代码生成模型,超越了 DeepSeek R1 和 OpenAI 的 o3 等模型。如果你是程序员,一定要第一时间切换过去,用下这款模型。

上周末,一则来自北京某医院神经外科主任医师的视频引发关注。据这位医师介绍,他曾用 DeepSeek 协助诊断了一位超复杂脑瘤患者的病情,并给出了超高评价:“对于这种较为深入的医学问题,DeepSeek 至少展现出了与省级三甲医院专家相当的水平。”
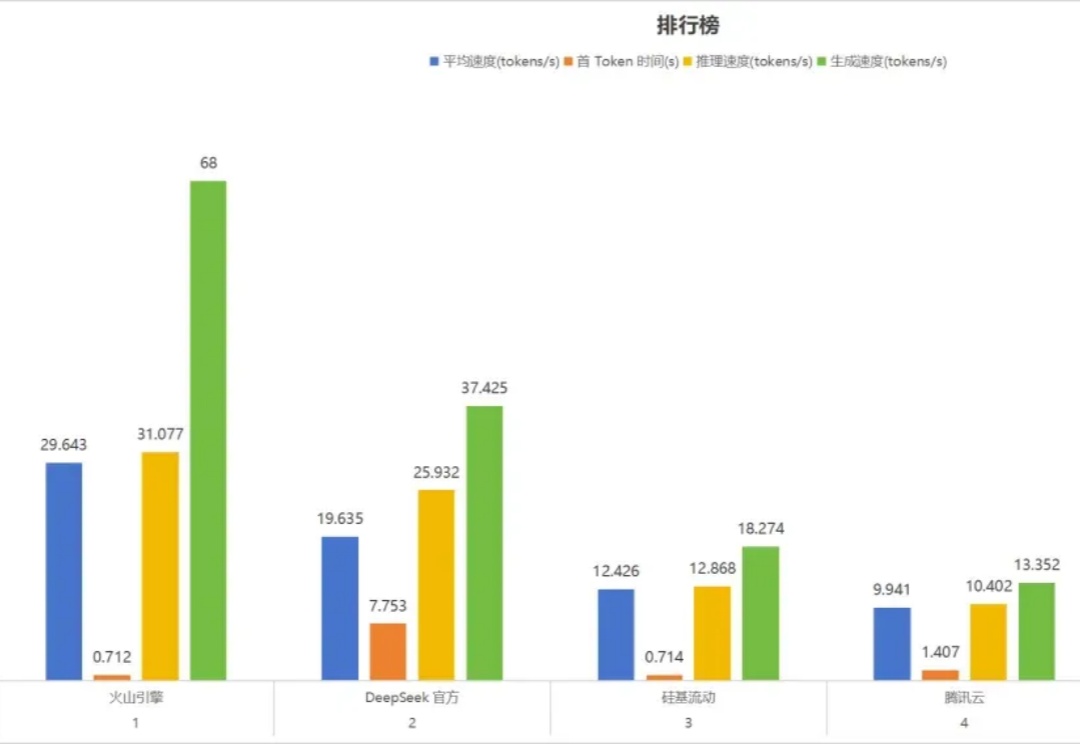
部署 DeepSeek 系列模型,尤其是推理模型 DeepSeek-R1,已经成为一股不可忽视的潮流。
这一波 DeepSeek 的泼天流量,各种大小公司都在吃。为什么,一夜之间,所有产品都在宣传自家接入了 DeepSeek 呢?主要原因是 DeepSeek 官网无法满足全世界人民日益增长的 DeepSeek 使用需求。
知名 Chatbot 及各种 AI 工具箱产品 Monica 最近推出了国内版Monica.cn,基于 DeepSeek R1 与 V3模型,并且具备实时联网搜索与记忆能力。
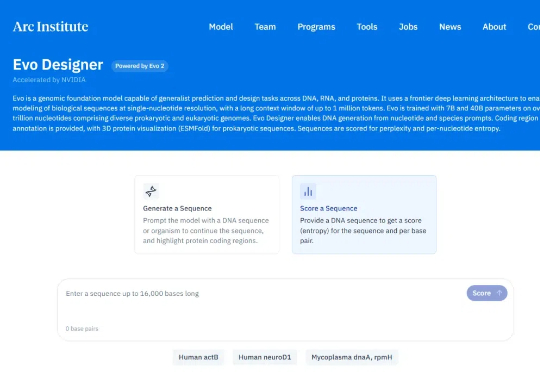
生物学大模型又迎新里程碑!2025 年 2 月 19 日,来自 Arc Institute、英伟达、斯坦福大学、加州大学伯克利分校和加州大学旧金山分校的科学家们,联合发布了生物学大模型 Evo2。
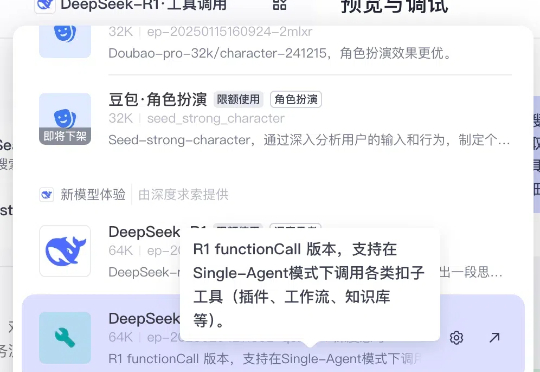
众所周知,目前 DeepSeek R1 有一个很大的痛点是不支持 Function Call 的。GitHub 上有许多开发者都表达了这一诉求。